Lavergne
Gérer les hiérarchies déséquilibrées
2023-01-18

On est habitué à utiliser des hiérarchies où la somme des éléments d’un niveau donne le résultat pour le niveau parent. Par exemple le CA de chaque produit vendu dans une boutique donne le CA de la boutique ; le CA de toutes les boutiques dans un pays donne le CA du pays. Mais certaines hiérarchies ne fonctionnent pas comme ça :
- Si la valeur mesurée n’est pas additive, c’est-à-dire que la valeur d’un parent ne correspond pas à la somme des valeurs de ses enfants.
- Si la hiérarchie n’est pas équilibrée : que certaines branches ont plus de niveaux que d’autres.
Dans ces deux cas une agrégation naturelle n’est pas possible, il faut adapter la donnée ou son traitement.
Valeurs non-additives
Pour les valeurs non-additives on peut ajouter des valeurs de régulation pour corriger les écarts entre les sous-niveaux et le total. Par exemple, si j’ai une hiérarchie Pays –> Boutique et que je veux afficher les valeurs :
- Pays = FR : CA = 123
- Boutique = Paris : CA = 67
- Boutique = Lyon : CA = 38
- Boutique = Perpignan : CA = 15
Si j’intègre les données correctement :
| Pays | Boutique | CA |
|---|---|---|
| FR | Paris | 67 |
| FR | Lyon | 38 |
| FR | Perpignan | 15 |
Dans ce cas le cumulé des boutiques est 120. Mais je veux afficher 123 (ne me demandez pas pourquoi, c’est le problème du comptable). Je dois donc ajouter une ligne de régulation :
| Pays | Boutique | CA |
|---|---|---|
| FR | Paris | 67 |
| FR | Lyon | 38 |
| FR | Perpignan | 15 |
| FR | NA | 3 |
└───FR = 123
├───Paris = 67
├───Lyon = 38
├───Perpigna = 15
└───NA = 3
Néanmoins la vérification des données et l’ajout de chaque ligne de régulation peuvent être très fastidieux et couteux dès qu’on a plusieurs catégories et plusieurs niveaux. On risque aussi d’ajouter des erreurs dans les données alors qu’elles nous ont toutes été fournies est qu’il ne devrait pas être nécessaire de les recalculer. Enfin, la régulation sera visible, ce qui n’est pas toujours souhaité par l’utilisateur.
Hiérarchie non-équilibrée
Lorsqu’on a un nombre de niveaux différent dans les branches d’une hiérarchie, la solution la plus courante est d’ajouter des niveaux fictifs pour égaliser les branches. Si dans ma base de données, j’ai en plus des données de la France, les valeurs d’autres pays mais sans le détail par boutique :
- Pays = ES : CA = 80
- Pays = IT : CA = 55
Pour intégrer les données je vais devoir préciser une boutique pour ces pays : Pays | Boutique | CA — | — | — FR | Paris | 67 FR | Lyon | 38 FR | Perpignan | 15 FR | NA | 3 ES | Boutiques ES | 80 IT | Boutiques IT | 55
├───FR = 123
│ ├───Paris = 67
│ ├───Lyon = 38
│ ├───Perpignan = 15
│ └───NA = 3
├───ES = 80
│ └───Boutiques ES = 80
└───IT = 55
└───Boutiques IT = 55
La bonne méthode
La méthode idéale (à mon avis) pour traiter les deux situations décrites ci-dessus est d’intégrer l’ensemble des données, sans régulation, pour recréer la hiérarchie et les mesures en DAX.
Par exemple, on souhaite analyser l’efficacité d’une population pour exécuter une tâche quelconque. Les personnes sont rassemblées en sections, plusieurs sections forment une équipe, plusieurs équipes forment un groupe. Mais les groupes peuvent aussi être un ensemble de personnes sans répartition par équipe. Et les équipes peuvent être un ensemble de personnes sans répartition par section On a deux mesures :
- Eff : efficacité dans la tâche, exprimée en pourcentage, la valeur n’est pas additive : le résultat d’une équipe est indépendant des résultats des sections qui la composent.
- Pax : le nombre de personnes, la valeur est additive : le nombre de personnes dans une équipe correspond à la somme du nombre de personnes dans les sections qui la composent.
└───Root : Eff = 55% / Pax = 35
├───Grp_A : Eff = 60% / Pax = 9
│ ├───Eqp_A1 : Eff = 40% / Pax = 5
│ └───Eqp_A2 : Eff = 70% / Pax = 4
│ ├───Sec_A2_ker : Eff = 75% / Pax = 2
│ └───Sec_A2_bis : Eff = 55% / Pax = 2
├───Grp_B : Eff = 65% / Pax = 16
│ ├───Eqp_B1 : Eff = 40% / Pax = 6
│ │ ├───Sec_B1_ker : Eff = 70% / Pax = 2
│ │ ├───Sec_B1_bis : Eff = 40% / Pax = 2
│ │ └───Sec_B1_ter : Eff = 20% / Pax = 2
│ ├───Eqp_B2 : Eff = 35% / Pax = 5
│ └───Eqp_B3 : Eff = 30% / Pax = 5
└───Grp_C : Eff = 30% / Pax = 10
Les données en entrée
On récupère les données au format tabulaire : Elément | Parent | ValeurA | ValeurB | ...
| Elément | Parent | Eff | Pax |
|---|---|---|---|
| Root | null | 55 | null |
| Grp_A | Root | 60 | null |
| Eqp_A1 | Grp_A | 40 | 5 |
| Eqp_A2 | Grp_A | 70 | null |
| Sec_A2_ker | Eqp_A2 | 75 | 2 |
| Sec_A2_bis | Eqp_A2 | 55 | 2 |
| Grp_B | Root | 65 | null |
| Eqp_B1 | Grp_B | 40 | null |
| Sec_B1_ker | Eqp_B1 | 70 | 2 |
| Sec_B1_bis | Eqp_B1 | 40 | 2 |
| Sec_B1_ter | Eqp_B1 | 20 | 2 |
| Eqp_B2 | Grp_B | 35 | 5 |
| Eqp_B3 | Grp_B | 30 | 5 |
| Grp_C | Root | 30 | 10 |
Il est important que la racine de la hiérarchie (Root) soit une valeur nulle comme parent (et pas une valeur vide). Il est possible d’avoir plusieurs racines qui sont chacunes au début d’une hiérarchie.
On ajoute également une colonne d’index.
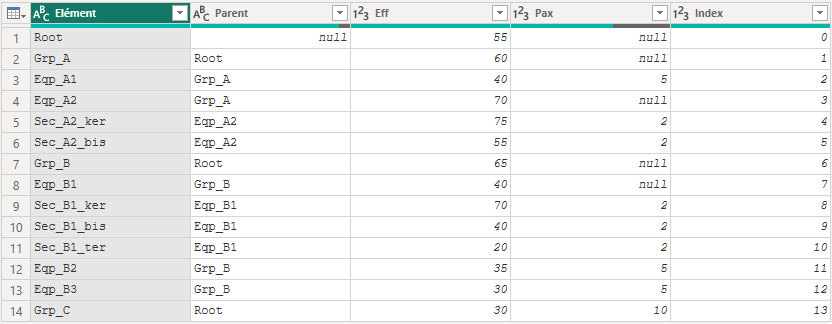
Colonnes calculées
Un fois la table chargée dans le modèle, on va créer plusieurs colonnes et mesures pour rendre la hiérarchie facilement utilisable. Pour cela on va notamment utiliser les fonctions parents et enfants.
- Path : Crée le chemin de l’élément à partir de la racine. Les niveaux sont séparés par des tubes.
Path = PATH(AnalysePerf[Elément], AnalysePerf[Parent]) - Depth : Enregistre la profondeur de l’élément : 1 pour la racine, 2 pour les groupes, 3 pour les équipes …
Depth = PATHLENGTH(AnalysePerf[Path]) - Leaf : Indique si l’élément est une feuille dans la hiérarchie (s’il n’a pas d’enfant). Pour une utilisation plus simple dans les filtres, la colonne est de type entier plutôt que booléen.
Leaf = IF(COUNTROWS(FILTER(AnalysePerf, PATHCONTAINS(AnalysePerf[Path], EARLIER(AnalysePerf[Elément])))) = 1, 1, 0)
On va à présent recomposer la hiérarchie en ajoutant une colonne par niveau. Il y a 4 niveaux dans notre exemple, il faut donc ajouter 4 colonnes.
Niveau 1 = PATHITEM(AnalysePerf[Path], 1)
Niveau 2 = PATHITEM(AnalysePerf[Path], 2)
Niveau 3 = PATHITEM(AnalysePerf[Path], 3)
Niveau 4 = PATHITEM(AnalysePerf[Path], 4)
Les colonnes créées peuvent être réunies dans une hiérarchie.
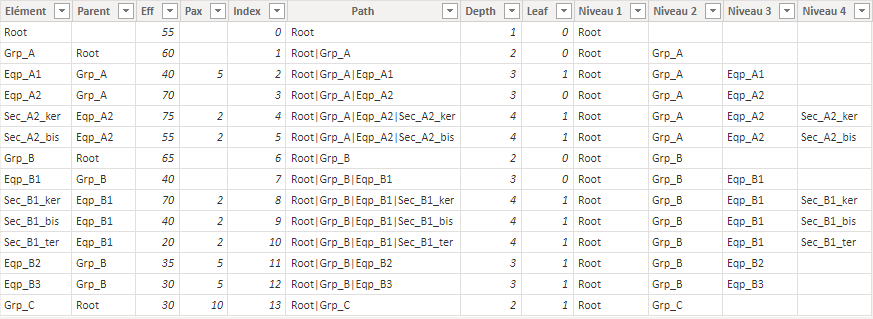
NB : La méthode pour répéter les niveaux à la place de valeurs vides est décrite plus bas.
Champs calculés
La table est prète à être utilisée, on va créer les mesures qui vont gérer les valeurs non-additives et additives.
- RowDepth : la profondeur de la ligne dans la table source.
RowDepth = MIN(AnalysePerf[Depth]) - BrowseDepth : la profondeur dans la hiérarchie du niveau affiché.
BrowseDepth = SWITCH(TRUE() , ISINSCOPE(AnalysePerf[Niveau 4]), 4 , ISINSCOPE(AnalysePerf[Niveau 3]), 3 , ISINSCOPE(AnalysePerf[Niveau 2]), 2 , ISINSCOPE(AnalysePerf[Niveau 1]), 1 ) - RowPath : le chemin de la ligne en cours dans la hiérarchie.
RowPath = FIRSTNONBLANK(AnalysePerf[Path], TRUE())
Indicateurs version 1
- Val Eff : pour les valeurs non-additives ; la valeur de la colonne Eff pour l’élément du niveau observé (et pas pour tous ses enfants) :
Val Eff = VAR _d = [BrowseDepth] RETURN CALCULATE(SUM(AnalysePerf[Eff]), FILTER(AnalysePerf, [Depth] = _d)) - Val Pax : pour les valeurs additives ; la somme du nombre de personne pour les éléments les plus bas uniquement. Pax est une colonne qui peut être additionné, on filtre pour ne garder le niveau le plus fin dans l’hypothèse où des niveaux agrégés auraient également été renseignés.
Val Pax = IF([BrowseDepth] >= MIN(AnalysePerf[Depth]) && [BrowseDepth] <= MAX(AnalysePerf[Depth]) , CALCULATE(SUM(AnalysePerf[Pax]), FILTER(AnalysePerf, AnalysePerf[Leaf] = 1)) )
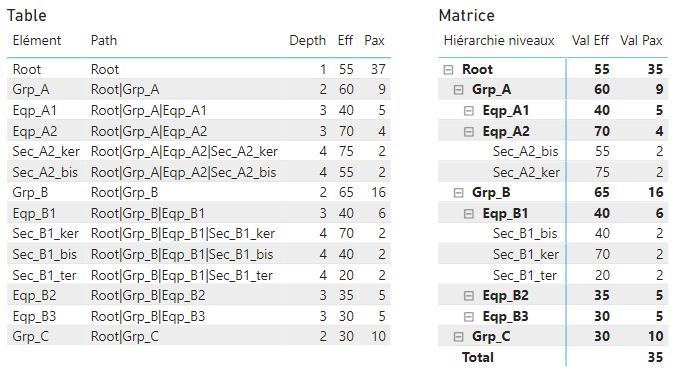
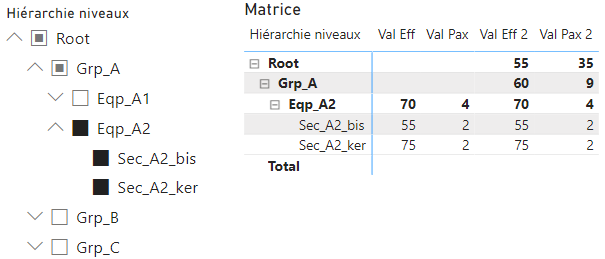
Attention, en filtrant sur un élément en particulier de la hiérarchie : les mesures renvoient des valeurs uniquement pour cet élément et ses enfants. Par exemple si je sélectionne Eqp_2 j’aurai le résultat pour Eqp_2, Sec_A2_ker et Sec_A2_bis. Pour les niveaux supérieurs je n’ai pas de données. Ce comportement n’est pas incohérent et est celui attendu dans la plupart des cas.
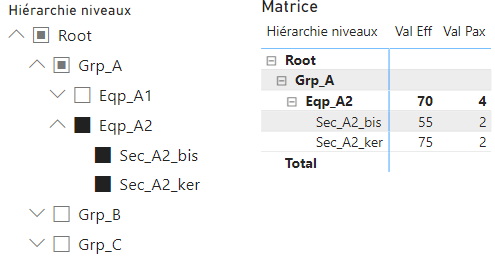
Indicateurs version 2 : conservation des totaux
Si on souhaite afficher les valeurs des niveaux supérieurs (les totaux), lorsque la hiérarchie est filtrée, il faut modifier les mesures :
- Val Eff version 2 : pour les valeurs non-additives ; le chemin courant est récupéré pour être appliqué quelques soient les filtres.
Val Eff 2 = VAR _path = [RowPath] VAR _d = [BrowseDepth] RETURN CALCULATE(SUM(AnalysePerf[Eff]), FILTER(ALL(AnalysePerf), AnalysePerf[Depth] = _d && PATHCONTAINS(_path, [Elément]))) - Val Pax version 2 : pour les valeurs additives ; l’élément courant est récupéré pour appliquer un calcul similaire à la version 1 en prenant en compte les descendants de l’élément.
Val Pax 2 = VAR _d = [BrowseDepth] RETURN If(_d, VAR _p = [RowPath] VAR _e = MINX(FILTER(ALL(AnalysePerf), AnalysePerf[Depth] = _d && PATHCONTAINS(_p, AnalysePerf[Elément])), [Elément]) RETURN CALCULATE(SUM(AnalysePerf[Pax]), FILTER(ALL(AnalysePerf), PATHCONTAINS(AnalysePerf[Path], _e) && AnalysePerf[Leaf] = 1)) )
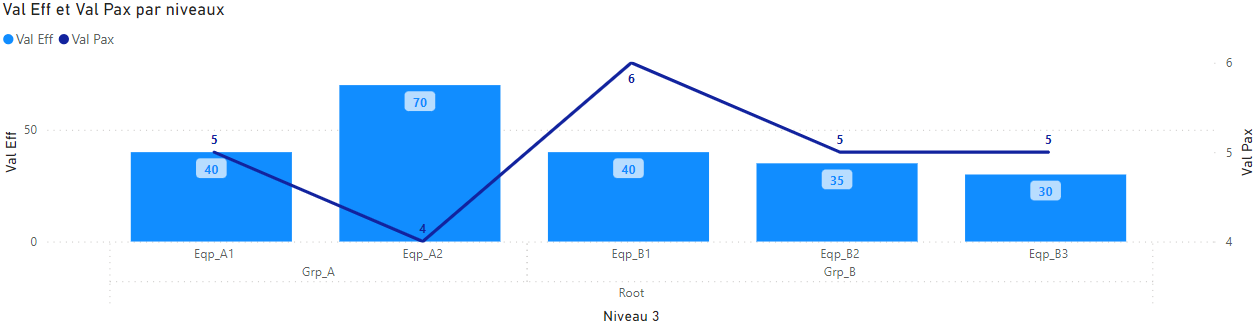
Indicateurs version 3 : répétition des parents
Si on affiche ces mesures dans un histogramme, seules les valeurs pour le niveau en cours sont visibles. Par exemple si on se place dans la hiérarchie au niveau 3 (Eqp_A1, Eqp_A2, etc.) on ne verra pas de résultat pour l’élément Grp_C qui ne contient pas de niveau enfant.
Si on souhaite afficher les éléments parents dans le visuel il faut à nouveau modifier les mesures. On reprend la version 2 des mesures et on remplace l’appel à [BrowseDepth] par le calcul MIN([BrowseDepth], [RowDepth]) : on garde le plus petit niveau entre les deux indicateurs.
- Val Eff version 3 : pour les valeurs non-additives ; le chemin courant est récupéré pour être appliqué quelques soient les filtres.
Val Eff 3 = VAR _path = [RowPath] VAR _d = MIN([BrowseDepth], [RowDepth]) RETURN CALCULATE(SUM(AnalysePerf[Eff]), FILTER(ALL(AnalysePerf), AnalysePerf[Depth] = _d && PATHCONTAINS(_path, [Elément]))) - Val Pax version 3 : pour les valeurs additives ; l’élément courant est récupéré pour appliquer un calcul similaire à la version 1 en prenant en compte les descendant de l’élément.
Val Pax 3 = VAR _d = MIN([BrowseDepth], [RowDepth]) RETURN If(_d, VAR _p = [RowPath] VAR _e = MINX(FILTER(ALL(AnalysePerf), AnalysePerf[Depth] = _d && PATHCONTAINS(_p, AnalysePerf[Elément])), [Elément]) RETURN CALCULATE(SUM(AnalysePerf[Pax]), FILTER(ALL(AnalysePerf), PATHCONTAINS(AnalysePerf[Path], _e) && AnalysePerf[Leaf] = 1)) )
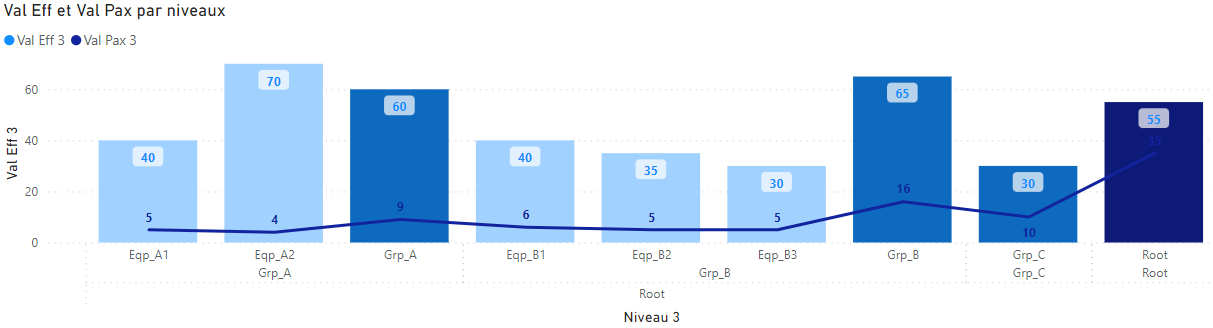
Indicateurs v1, v2 & v3
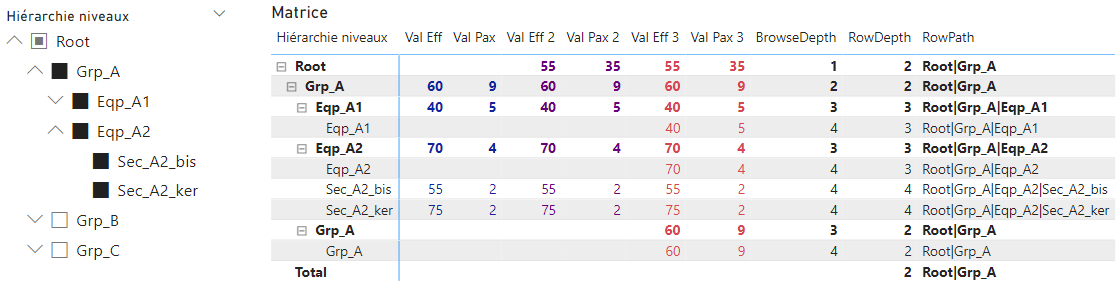
Segments
Le visuel Segment dans Power BI affiche tous les niveaux d’une hiérarchie. Si on l’utilise pour afficher les 4 niveaux, des valeurs (Vide) seront affichées pour chaque niveau. Il faut donc filtrer ces valeurs.
La mesure BrowseDepth est non nulle lorsqu’il faut afficher le niveau, on pourrait vouloir l’utiliser pour filtrer le segment. Mais en faisant cela on ne garde que les branches de la hiérarchie avec des niveaux complets (de 1 à 4) ; en effet le visuel segment n’affiche que des branches complètes. Ce n’est donc pas la bonne solution.
On peut utiliser la colonne Leaf pour ne conserver que les éléments qui terminent une branche. Dans ce cas on ne perd pas d’élément dans la hiérarchie. Mais les braches incomplètes (avec moins de 4 niveaux) comportent des valeurs (Vide).
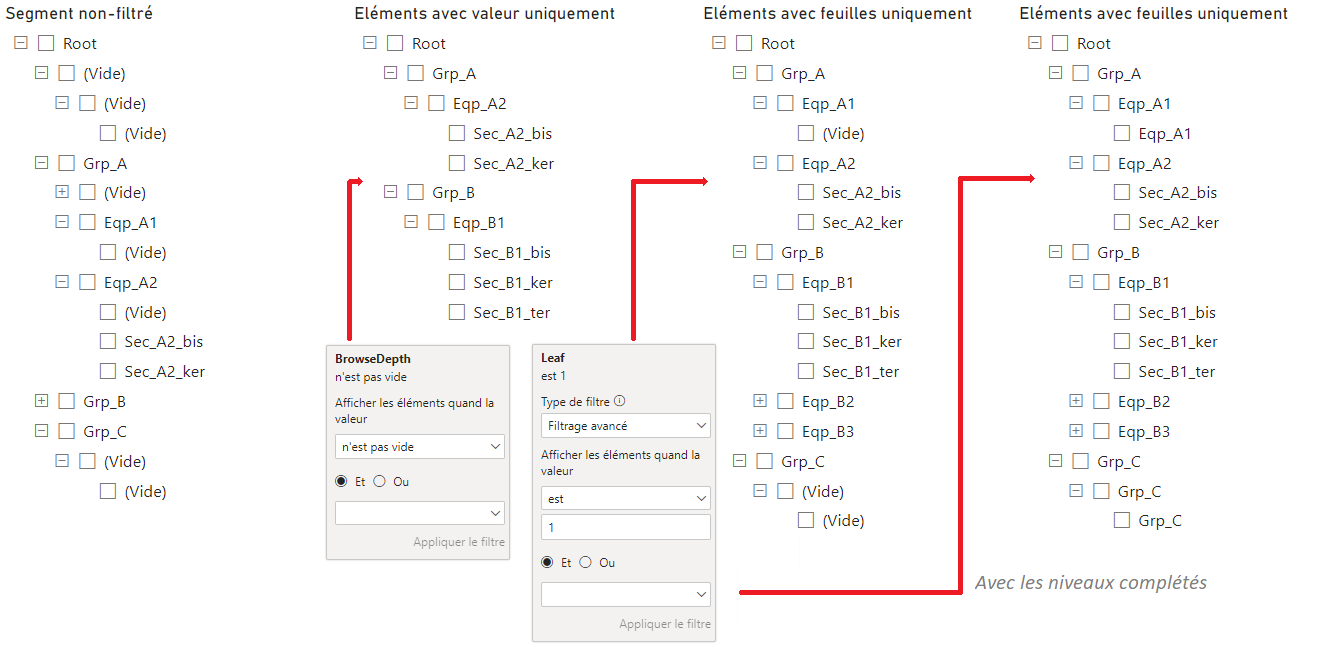
On remplace ses valeurs (Vide) en “complétant” les branches. Si un niveau est vide, on prend le nom du niveau précédent :
Niveau 1 = PATHITEM(AnalysePerf[Path], 1)
Niveau 2 = IF(PATHITEM(AnalysePerf[Path], 2) <> "", PATHITEM(AnalysePerf[Path], 2), [Niveau 1])
Niveau 3 = IF(PATHITEM(AnalysePerf[Path], 3) <> "", PATHITEM(AnalysePerf[Path], 3), [Niveau 2])
Niveau 4 = IF(PATHITEM(AnalysePerf[Path], 4) <> "", PATHITEM(AnalysePerf[Path], 4), [Niveau 3])